
信息发布
NEWS AND EVENTS
强化学习中环境模型利用新机制【AAAI 2021】
发布时间: 2020-12-31
近日,中科院自动化所智能系统中心团队在机器学习领域顶级会议AAAI发表论文Learning to reweight imaginary transitions for model-based reinforcement learning。团队针对强化学习中环境建模偏差带来的瓶颈问题,提出了一种可学习的模型利用机制:通过训练一个权重网络来调整环境模型生成样本的权重,使得重加权后的生成样本对策略优化过程的负面影响最小化。在MUJOCO环境多个强化学习任务上,该方法达到的效果超过当前最优的基于模型(model-based)和无模型(model-free)的强化学习方法。

强化学习主要用于解决智能体(agent)如何与环境进行交互从而最大化回报的问题。强化学习方法可分为两类:无模型方法和基于模型的方法。前者直接使用智能体与环境交互产生的轨迹来更新策略,其在许多复杂控制任务上均取得了优秀的效果[1-2],但该类方法的训练往往需要大量的交互数据,这一缺陷限制了该类方法的应用场景。针对这一缺陷,后者先使用交互产生的轨迹来训练一个动力学模型(dynamics model),然后用该模型模拟环境随智能体行动而产生的状态变化和反馈的奖励。这样的模型可以用于智能体决策时的实时规划,也可以用于生成大量虚拟轨迹来进行策略更新。基于此,学习到最优策略所需的真实交互数据就会减少。
然而,基于模型的强化学习方法所能达到的性能上限却受限于学习到的动力学模型的预测精度。模型误差往往会导致强化学习算法陷入局部最优,甚至可能导致训练过程崩溃。之前的研究工作[3-5]考虑调整动力学模型的利用方式,以此来减小模型误差对策略优化过程的影响,例如:只使用预测不确定度低的虚拟样本来更新策略[4]等。但这些调整方案都是预先设定的固定方案,无法在策略优化过程中自适应地调整,这导致算法需要较多的人工参与,并且存在生成数据浪费的情况,例如:当策略价值评估偏差较大时,带有少量预测偏差的虚拟样本也能用于训练。
该研究工作希望在抑制模型误差对策略优化过程产生负面影响的同时最大化地利用这些生成数据,从而提出根据每个生成样本对策略优化过程的影响来调整它们各自的权重。受“交叉验证”思想的启发,作者尝试构建以下流程来调整权重:针对每个生成样本,首先,使用它来更新价值和策略网络;然后,在真实数据上计算神经网络更新前后损失值的变化;最后,根据损失值的变化调整该样本的权重,例如:损失值减小,则说明该样本对神经网络的训练起正面作用,应该增加该样本的权重,反之则减少。显然,上述流程的计算代价极大。为了高效地实现这一权重调节机制,作者引入一个权重预测网络(网络结构如图1(右)所示),并按照上述流程对该网络进行训练:使用权重预测网络对一批生成样本进行权重预测,使用加权后的样本更新价值和策略网络,以更新前后损失值的变化作为优化目标,按照链式法则计算梯度并更新权重预测网络(算法的整体框架如图1(左)所示)。
在MUJOCO环境多个强化学习任务上,文中的方法取得的效果超过当前最优的基于模型和无模型的强化学习方法(如图2所示)。此外,使用学习到的权重函数进行重加权后,价值网络的预测误差明显下降,说明该模型利用机制的确能减小模型误差对训练过程的负面影响。

图1:整体框架。权重预测网络的训练过程(左):计算价值网络在使用加权样本训练前后
的验证集上的损失值之差,并利用链式法则来更新权重预测网络。权重预测网络的网络结构
(右)针对生成序列中的每一个(当前状态,动作,下一状态,奖励)序对,序列化地预测权
重,输入信息包括:前驱序对的信息,当前状态,动作以及下一状态和奖励的不确定度估计。

图2:在MUJOCO环境中多个强化学习任务上,文中方法(ReW-PE-SAC) 可以达到了良好的性能
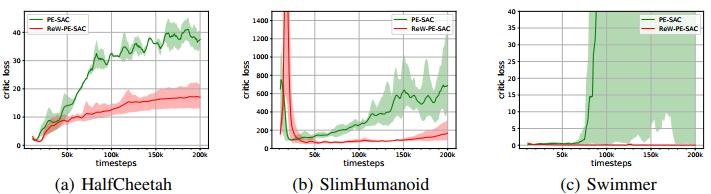
图3:使用文中方法(红色)进行重加权后,价值网络的预测误差明显下降
参考文献
[1] Mnih V, Kavukcuoglu K, Silver D, et al. Human-level control through deep reinforcement learning. Nature, 2015: 529-533.
[2] Haarnoja T, Zhou A, Abbeel P, et al. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. International Conference on Machine Learning, 2018: 1861-1870.
[3] Heess N, Wayne G, Silver D, et al. Learning continuous control policies by stochastic value gradients. Advances in Neural Information Processing Systems, 2015: 2944-2952.
[4] Kalweit G, Boedecker J. Uncertainty-driven imagination for continuous deep reinforcement learning. Conference on Robot Learning, 2017: 195-206.
[5] Janner M, Fu J, Zhang M, et al. When to trust your model: Model-based policy optimization. Advances in Neural Information Processing Systems, 2019: 12519-12530.

