
信息发布
NEWS AND EVENTS
强化学习中图像局部区域敏感的探索奖励【ToG 2021】
发布时间: 2021-12-16
近日,中科院自动化所智能系统与工程研究中心团队在游戏AI领域重要期刊IEEE Transactions on Games发表论文Deep Reinforcement Learning with Part-aware Exploration Bonus in Video Games。团队针对强化学习中的高维环境探索问题,提出了一种图像局部区域敏感的奖励构造机制:通过在标准的随机蒸馏网络中引入由注意力网络产生的与智能体决策相关的注意图,实现奖励信号对图像中局部重要区域的感知。团队在标准的强化学习 Atari 基准测试中的部分视频游戏上验证了方法的有效性。实验结果显示新方法与主流的探索方法相比实现了明显的性能提升。

强化学习算法依赖于精心设计的环境奖励。然而,具有稠密奖励的环境很少见,这促使学界设计鼓励探索的人工奖励。好奇心是一种成功的人工奖励函数,它使用预测误差作为奖励信号。在之前的工作中,用于产生人工奖励的预测问题在像素空间而不是可学习的特征空间中进行了优化,以避免特征变化引起的随机性。然而,这些方法忽略了图像中占比很小,但很重要的信息,比如角色位置的信息,这使得这些方法无法生成准确的人工奖励。在本文中,我们首先证实了为现有的基于预测的探索方法引入预训练特征的有效性,然后设计了一种注意力图机制来离散化在线学习的特征,从而保证在线学习特性的同时减少这一过程引起随机性对人工奖励的影响。
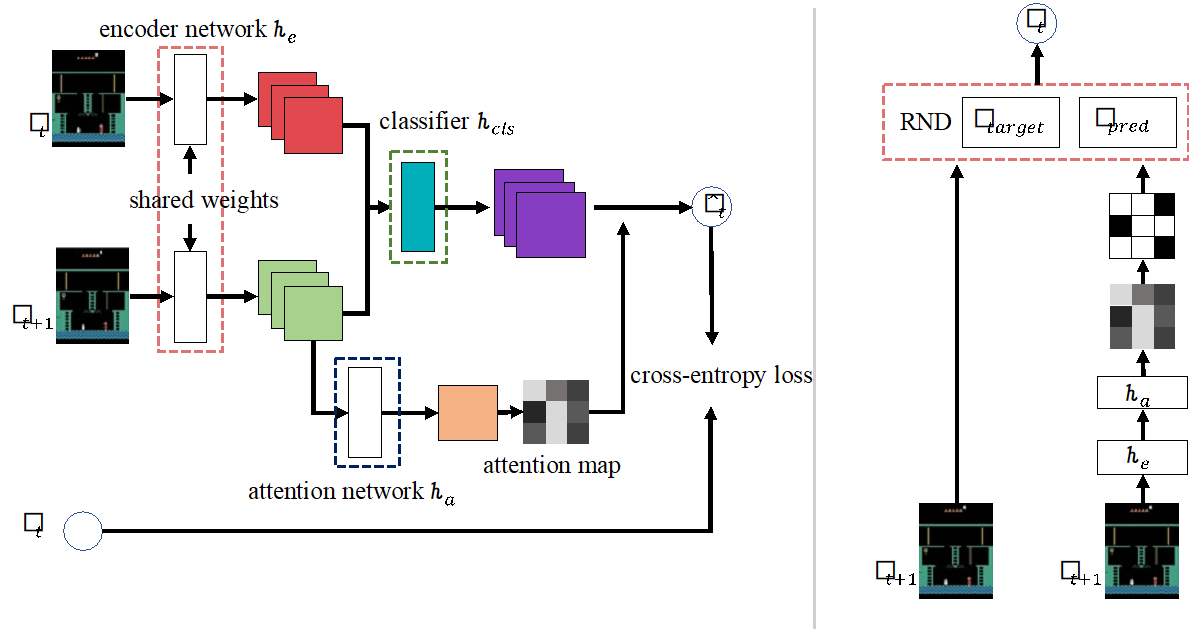
图表 1 方法流程图
我们的目标是构建一种基于预测误差的探索方法,该方法可以使用在线学习的特征来生成更准确的探索奖励。一个简单的想法是将学习到的特征作为预测问题的附加输入。但是,只有在整个训练期间使得将观测值映射到特征的编码函数参数固定时,此方法才有效。如果编码函数不断地变化,则同一观察相对应的特征在不同时间是不同的。这导致基于预测的探索方法无法对熟悉的观测值给出低的奖励,因为此时观测对应的特征编码是新颖的。这与基于误差的方法的基本思想背道而驰,即对熟悉的状态提供低的奖励,对新颖的状态提供高的奖励。
我们的核心思想是控制特征的变化范围,我们通过将连续空间中的学习到的特征映射到离散空间来实现这一目标。我们认为离散化可以缓解特征变化对基于奖励的方法的影响。我们进一步发现可以通过引入空间注意机制来以无监督的方式生成这种离散编码。具体来说,我们训练一个额外的网络生成注意力图。注意力图中的值表示观察的每个部分对代理任务的重要程度。之后,我们对注意力图中前n个大的元素取值为1,对其他元素取值为0,以获得与所学习特征相对应的离散编码。
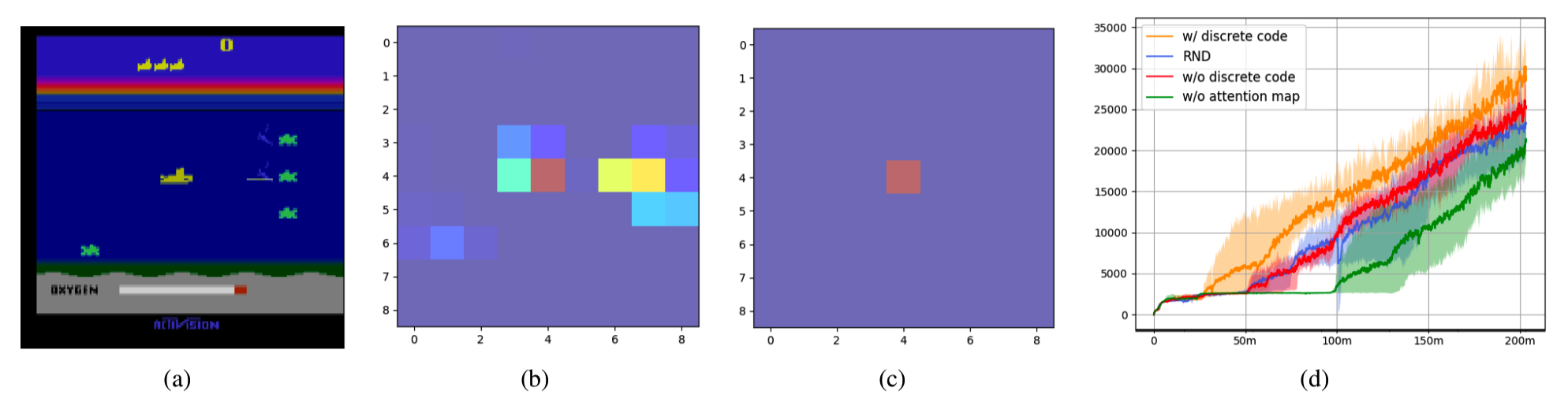
图表 2 注意力图示意以及不同输入对最终性能的影响

