
技术共享
TECHNOLOGY SHARING
提供开源算法 高水平基准AI
训练及复盘数据以及AI开发包等
DFP
强化学习、监督学习
开源实现
在强化学习算法中,学习是由一个标量奖励信号引导。在复杂的环境中,标量奖励可能是稀疏的和延迟的,不容易分辨哪个行动/行动序列获得了什么奖励信号,这就是所谓的信用分配问题。如果除了环境提供奖励外,还能获取到更丰富的、时间密集的多维反馈,可以帮助智能体训练学习到较好的策略,通过成功预测下一步获取的奖励,也可以大大减少智能体在策略学习中的搜索空间和迭代次数。DFP算法该算法在Visual Doom AI Competition 2016 中的 full deathmatch competition 获得第一名,主要是通过预测未来时间步的多维环境属性,用了更少的游戏内部数据的获取,在性能上高于第二名DRQN 50%。该方法引入目标作为输入结合监督学习方法,可针对不同的目标,并在预测上取得了一定的泛化性。
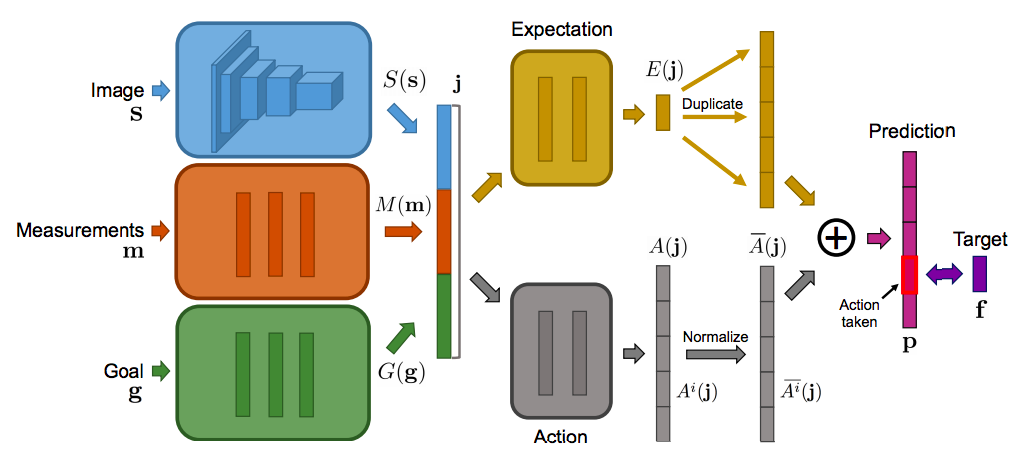
[1]Dosovitskiy, Alexey, and Vladlen Koltun. "Learning to act by predicting the future." arXiv preprint arXiv:1611.01779 (2016).

