
社区论坛
Community Forum
本文转载自微信公众号“人机与认知实验室”(ID: 9h_9c3c1f805cb8),作者刘伟
机器翻译,正在弥补人机翻译之间的差距
本文摘自米歇尔·梅拉妮新书《AI3.0》
我们应该在多大程度上相信机器实际上真的在慢慢学会理解语义,或者说机器翻译的准确性正在迅速接近人类水平?为了回答这个问题,让我们更加仔细地去看这些声明所依据的事实。首先,我们应该弄清楚这些公司如何衡量一台机器或一个人的翻译质量。评估翻译质量并非那么简单明了,一段给定的文本可以有很多种正确的翻译方式,当然,也有更多错误的翻译方式。由于对给定的文本进行翻译没有唯一的正确答案,因此很难设计出一种能够自动评估系统翻译准确性的方法。
谷歌声称其于2016年推出的神经机器翻译这种新方法弥补了人和机器翻译之间的差距。另外几家大型科技公司迎头赶上,也陆续创造了他们自己的在线机器翻译程序,同样是基于编码器-解码器的架构。这些公司以及为其报道的科技媒体,都在热情地推广这些翻译服务。《麻省理工科技评论》杂志报道称:“谷歌的这一新服务几乎可以像人类一样翻译语言。”微软在一场公司推介会上表示其中文对英文新闻翻译服务的水平已经和人类相当。IBM宣称:“沃森现在能流利地说9种语言,且这个数量仍在增加。”Facebook负责语言翻译的高管坦言:“我们相信神经网络正在学着理解语言的潜在语义。”专业翻译公司DeepL的首席执行官吹嘘道:“我们的机器翻译神经网络已经发展出惊人的理解力。”
总体来说,这些声明在一定程度上是由科技公司多种多样的人工智能服务在销售方面的竞争所推动的,而语言翻译是其中一项盈利潜力很大的主要服务。虽然像谷歌翻译这样的网站会提供针对少量文本的免费翻译服务,但如果一家公司想要翻译大量文档或在自己的网站上为客户提供翻译,则需要使用收费的机器翻译服务,所有这些服务都由相同的编码器-解码器架构提供支持。
随着深度学习的引入,机器翻译的水平已经得到很大提升。那么这样就能证明机器翻译现在已接近人类水平了吗?在我看来,这种声明从好几个方面看来都是不合理的。首先,对评分取平均数会产生误导性。比如,对于机器翻译来说,尽管其对大多数句子的翻译被评为“好极了”,但也有许多句子被评为“糟透了”,那么其平均水平是“还不错”,然而,你可能更想要一个总是表现得相当好、从来不会出错的、更可靠的翻译系统。
其次,这些翻译系统接近人类水平或与人类水平相当的说法完全是基于其对单个句子翻译水平的评估,而非篇幅更长的文章的翻译。在一篇文章中,句子通常会以重要的方式相互依存,而在对单个句子翻译的过程中,这些可能会被忽略。我还没有看到过任何关于机器翻译长文的评估的正式研究,一般来说,机器翻译长文的质量会差一点,比如说,对于谷歌翻译,当给定的是整个段落而非单个句子时,其翻译质量会显著下降。
最后,这些评估所使用的句子都是从新闻报道和维基百科页面中提取的,这些页面通常都经过慎重的编写以避免使用有歧义的语言或习语。这样的语言可能会给机器翻译系统带来严重的问题,但在现实世界中是无法回避的。

迷失在翻译之中
还记得我在上一章开头提到的《餐厅际遇》的故事吗?我并不是为了测试翻译系统才设计这个故事的,但这个故事的确很出色地阐明了机器翻译系统面临的挑战——口语、习语和有歧义的语言。
我用谷歌翻译把《餐厅际遇》从英语翻译成三种目标语言:法语、意大利语和中文。我把不带原文的翻译结果发给了我那些同时懂英语和目标语言的朋友们,并请他们把谷歌翻译的翻译结果再翻译回英语,以便了解一个熟练掌握相应目标语言的人会从谷歌翻译后的文本中得到什么。在这里,为了读者的阅读乐趣,我在下方列出了一些翻译结果。
原本的故事:
A man went into a restaurant andordered a hamburger, cooked rare. When it arrived, it was burned to a crisp. Thewaitress stopped by the man ‘stable. “Is burger okay? “she asked. “Oh, it’s justgreat,” the man said, pushing back his chair and storming out of the restaurantWithout paying. The waitress yelled after him, “Hey, what about the bill?” She shruggedher shoulders, muttering under her breath, “Why is he so bent out of shape?“(一位男士走进一家餐厅,点了一个汉堡包,要两分熟的。当汉堡包上桌时,它是烤糊了的。女服务生在这位男士的桌子旁停下,并问道:“汉堡包还可以吗?”“哦,它简直太好了!”这个人说着,把椅子推到后面,没有付钱就冲出了餐厅。女服务生在他后面喊道:“嘿,账单怎么办?”她耸了耸肩,小声嘀咕着:“他为什么如此愤怒?”)
谷歌翻译提供的法语版本,以及再由人工将其翻译为英语的版本:
英语版本
A man entered a restaurant andordered a hamburger, cooked infrequent. When he arrived, he got burned at acrunchy. The waitress stopped walking in front of the man’ stable. “Is the hamburgerdoing well? “She asked. “Oh, it’ terrific,” said the man while putting his chairback and while going out of the restaurant without paying. The waitress shoutedafter him, “say, what about he proposed legislation? “She shrugged her shoulders,mumbling in her breath,“Why is he so distorted?”(一位男士走进一家餐厅并点了一个汉堡包,少见做法。当他到达的时候,他被烧焦了,并发出嘎吱嘎吱的响声。女服务生在这个人的桌子前停下来。“汉堡包做得好吗?”她问。“哦,它太棒了!”那人一边把椅子放回去,一边不付钱就走出餐厅。女服务生在他后面喊道:“喂,提议的法规怎么样了?”她耸耸肩,喃喃自语道:“他为什么这么扭曲?”)
阅读这些翻译,就像听一个才华横溢但又频频出错的钢琴家演奏一段我们熟悉的旋律,这段旋律总体来说是可辨认的,但又是支离破碎的,令人不舒服,这首曲子在短时爆发时表现得很优美,但却总被刺耳的错误音符打断。谷歌翻译有时还会在一些多义词上选择错误的意思,例如将“rare”(半熟的)和“bill”(账单)翻译成了“不常见”和“提议的法规”,这种情况之所以会发生,主要是因为程序忽略了这些词语所处的上下文。“烤糊了”(burnedto a crisp)和“愤怒”(bent out of shape)等习语的翻译方式都很奇怪,该程序似乎无法在目标语言中找到对应的习语,或弄清楚该习语的实际含义。
虽然以上这些译文都把故事的梗概表达出来了,但一些细微且重要的部分在所有的翻译版本中都有丢失,包括把男士的愤怒表达为“冲出餐厅”,以及把女服务生的不满表达为“小声嘟囔着”,更不用说正确的语法偶尔也会在翻译过程中丢失。
我并不是有意要专挑谷歌翻译的毛病,我也尝试了许多其他的在线翻译服务,得到了类似的结果。这并不奇怪,因为这些系统都使用几乎同样的编码器—解码器架构。另外,我要强调一点:我获得的这些翻译结果,代表的是这些翻译系统在某一时间的阶段性水平,它们的翻译能力一直在不断提升,上述这些翻译错误说不定在你阅读本文时已经被修复了。然而,我仍然认为机器翻译想要真正达到人类翻译员的水平,还有很长的路要走,除了在一些特定的细分领域中。对于机器翻译来说,主要的障碍在于:与语音识别系统的问题一样,机器翻译系统在执行任务时并没有真正“理解”它们正在处理的文本。在翻译以及语音识别中,一直存在这样的问题:为达到人类的水平,机器需要在多大程度上具备这种理解能力?侯世达认为:“翻译远比查字典和重新排列单词要复杂得多……要想做好翻译,机器需要对其所讨论的世界有一个心理模型。”例如,翻译《餐厅际遇》这个故事需要具有这样一个心理模型:当一个人不付钱就气冲冲地离开餐厅时,服务生更有可能对着他大吼要他支付账单,而不是说些提议法规的事。侯世达的这一观点在人工智能研究人员欧内斯特·戴维斯(Ernest Davis)和马库斯2015年的一篇文章中得到了回应:“机器翻译通常会涉及一些歧义问题,只有达到对文本的真正理解并运用现实世界的知识才能完成这项任务。”
一个编码器-解码器网络能够简单地通过接触更大的训练集以及构建更多的网络层,来获得必要的心理模型和对现实世界的认识吗?还是说需要通过一些完全不同的方法?这仍然是一个悬而未决的问题,也是在人工智能研究群体中引发了激烈辩论的主题。现在,我只想说,虽然神经机器翻译在许多应用领域中非常有效且实用,但是如果没有知识渊博的人类进行后期编辑,它们从根本上来说仍然是不可靠的。所以,我们在使用机器翻译时或多或少都会对其结果有所怀疑。比如,当我用谷歌翻译来把“take it with a grain of salt”(对结果有所怀疑)这个短语从英文翻译成中文,然后再翻译回英文时,它变成了“bring a salt bar”(带一个盐条),真是有意思。[1]
把图像翻译成句子
有一个疯狂的想法:除了在语言之间进行翻译之外,我们能否训练一个类似于编码器-解码器架构的神经网络,使其学会把图像翻译成语言?其思想是:先使用一个网络对图像进行编码,再使用另一个网络来把它“翻译”成描述该图像内容的句子。毕竟,为一个图像创建标题不就是一种翻译方式吗?只不过这种情况下的源语言与目标语言分别是一幅画和一个标题。
事实证明,这个想法也没有那么疯狂。2015年,两个分别来自谷歌和斯坦福大学的团队,在同一个计算机视觉会议上围绕这个主题彼此独立地发表了非常类似的论文。在这里,我将描述由谷歌团队研发的叫作“Show and Tell”(展示和说明)的系统,因为它在概念上更简单一些。
图12-2给出了这个系统的工作原理框架图22。它类似于图12-1中的编码器解码器系统,只不过这里的输入是一幅图像而不是一个句子。图像被输入到一个卷积神经网络(Conv Net)而非编码器网络中。这里的Conv Nets与我在第04章中描述的那个类似,只是这个Conv Nets并不输出对于图像的分类,而是将其最后一层的激活值作为输入提供给解码器网络,随后,解码器网络解码这些激活值来输出一个句子。为了编码图像,研发团队使用了一个经ImageNet(我在第05章中描述过的一个大型图像数据集)图像分类任务训练过的Conv Nets,其任务是训练解码器网络为输入图像生成一段合适的字幕。
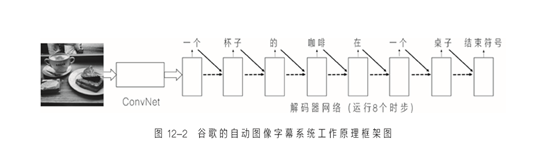
这个系统如何学习为图像生成合适的字幕呢?回想一下不同语言之间互译的原理:训练数据由成对的句子组成,句子对中的第一个句子用的是源语言,第二个句子是人类翻译员使用目标语言对源语言进行翻译的结果。同样的道理,在为图像生成字幕的情形中,每个训练样本由一张图像和与它匹配的一段字幕组成。这些图片是从Flickr等公共图像存储库中下载的,其字幕是由谷歌为此项研究雇用的亚马逊土耳其机器人生成的。由于字幕可以非常多变,每张图像都由5个不同的人分别给出一段字幕。因此,每张图像在训练集中会出现5次,每次都与不同的字幕配对。图12-3展示了一个训练图像样本,以及由亚马逊土耳其机器人提供的字幕。

这个“Show and Tell”解码器网络在大概8万对“图像-字幕”样本上进行了训练。图12-4给出了其在测试图像上生成的一些字幕样本,这些测试图像不在系统的训练集中。
一台机器能够对由像素组成的图像生成如此准确的字幕,这样的表现太亮眼了,让人震惊,这就是我在《纽约时报》上第一次看到这些结果时的感觉。那篇文章的作者是记者约翰·马尔科夫(John Mark off)[2],他撰写了一篇言辞谨慎的评述文章,其中有一句话是这样写的:“两组科研团队分别独立工作,发明了一款能够识别和描述照片与视频中的内容的人工智能软件,其准确度比以往任何时候都要高,有时甚至可以媲美人类的理解能力。”
然而,有些媒体就没有那么严谨了。一家新闻网站宣称:“谷歌的人工智能现在给图像添加字幕的能力几乎和人类一样好。”其他公司也很快采用了类似的自动给图像添加字幕的技术,并发布了声明。微软宣称,“微软的研究人员处在对以下技术研发的前沿领域:自动识别图像中的物体、解释图像的情境,并为之写出一个准确的说明等”。微软甚至为他们的系统创建了一个线上的原型系统,叫作“CaptionBot”,CaptionBot的网站宣称:“我可以理解任何照片的内容,我将争取做得跟人类一样好。”
谷歌、微软和Facebook等公司开始讨论,这种技术在多大程度上可以被应用于为视力障碍人群提供自动图像标识服务。自动图像字幕生成存在着和机器翻译一样的性能表现两极分化的问题。当它表现得很好时,它看起来几近神奇,如图12-4所示,但其犯起错来却也可以从轻微偏离主题到完全的胡说八道,图12-5展示了一些示例。这些错误的字幕可能会让你发笑,但对于一个无法看到这些照片的盲人,就无法判断这些字幕是好是坏了。
尽管微软说它的CaptionBot能够“理解”任何照片的内容,但事实正好相反:即便它们给出的字幕是正确的,这些系统也无法从人类的角度来理解图像。当我给微软的CaptionBot看第4章开头的那张照片时,系统的输出是:一位男士抱着一条狗。还算对吧,除了“男士”的部分……令人更遗憾的是,这段描述漏掉了照片中关键的、有价值的点,漏掉了通过图像对我们自身、对我们的体验、对我们关于世界的情感和知识进行表达的方式,也就是说,它漏掉了这张照片的意义。

我确信这些系统的能力将随着研究人员应用更多的数据和算法而得到提升,然而,我认为字幕生成网络对图像中的内容还是缺乏基本的理解,这必然意味着:就像在机器翻译中的表现一样,这些系统仍然是不可信的。它们会在某些情况下运行得很好,但有时却会令人大失所望。此外,即便这些系统在大多情况下是正确的,但对于一幅蕴含丰富意义的图像,它们往往无法抓住其中的要点。
把句子按照情感进行分类、翻译文档和描述照片,尽管自然语言处理系统在这些任务上的水平还远不及人类,但对于完成许多现实世界中的任务还是很有用的,因此对于研发人员而言,这项工作有着很大的利润空间。可是,自然语言处理研究人员的终极梦想是设计能够实时地与用户进行流畅和灵活的互动的机器,尤其是,可以与用户进行交谈并回复他们的问题。下一章我们将会探讨创建一个能够解答我们所有疑问的人工智能系统所面临的挑战。
[1]Take something with a grain of salt,指不要完全相信或接受某种说法,即对某件事要持保留态度。“a grain of salt”字面含义为一粒盐,机器因此将该短语翻译为“带一个盐条”(bring a salt bar)。作者此处说“That might be a better idea.”,使用了双关语,意指应对机器翻译持更大的怀疑态度。——译者注
[2]马尔科夫的著作《人工智能简史》从多个维度描绘了人工智能从爆发到遭遇寒冬,再到野蛮生长的发展历程,直击工业机器人、救援机器人、无人驾驶汽车、语音助手等前沿领域,深入探讨了人工智能与智能增强(intelligence augmentation, IA)的密切关系。本书的中文简体字版已由湛庐策划,浙江人民出版社于2017年出版。——编者注

