
社区论坛
Community Forum
1.背景介绍
人机对抗智能门户网站上已经上线了基于A2C算法的兵棋基准AI,本篇基于该基准AI代码,讨论该代码调参的一些经验。
基准AI代码及代码教程见:http://turingai.ia.ac.cn/ai_center/show?mid=4
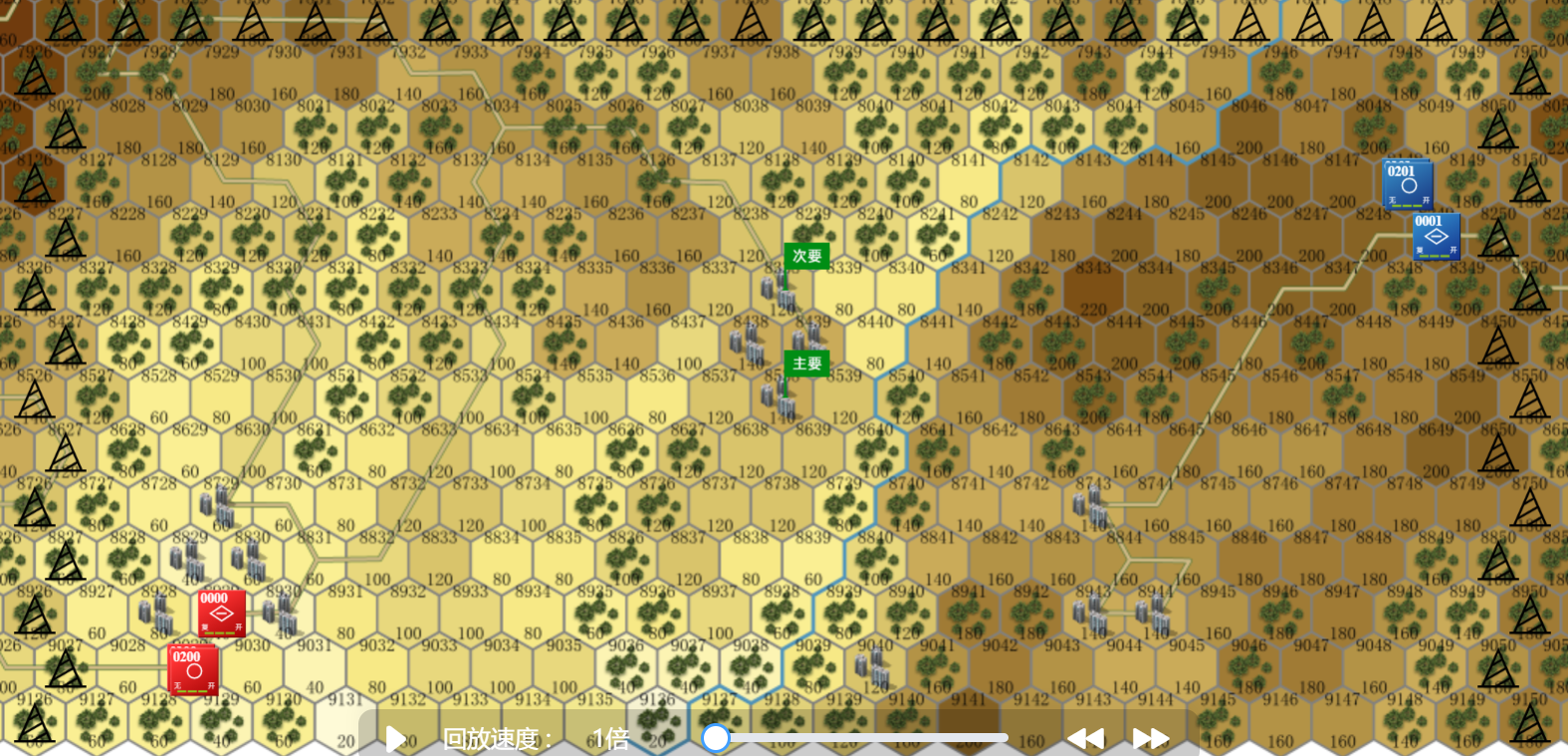
游戏环境图
2.参数概况
在兵棋强化学习的训练中会涉及到多个参数的调整,比如batchsize,学习率,网络调整,reward设置,loss系数等。这些参数在代码中都有体现,部分参数如下:
```
parser.add_argument('--batchsize', default=512, type=int)
parser.add_argument('--cross_policy_weights', default=0.25, type=float) # 0.00025 0.0025 0.025 0.25 2.5 连续值
```
3.探索程度调整
探索问题是强化学习中比较重要的问题。由于兵棋游戏不完美信息的博弈特点,探索程度的好坏对训练有很大的影响。
在本代码中影响探索程度的主要是策略熵loss,增大策略熵loss在整体loss中的权重可以增大前期的探索程度。
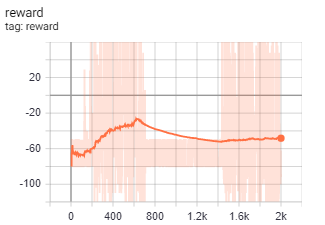
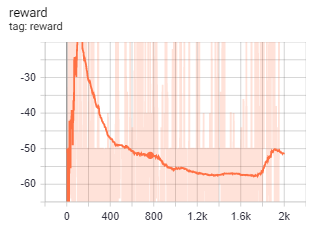
不同的loss权重会产生不同的reward曲线,上图分别是策略熵loss系数为0.025和2.5时候的reward曲线。
探索具体程度可以在复盘中进一步观察。
4.小节
增大探索系数在训练前期的复盘中可以看到各个算子探索的动作都较为均衡,这样也会产生很多没有实际效果的样本,比如本该迎敌作战,却因为探索系数的设置,去探索了回避的路线,但从长期训练来看,合理的探索有助于得到良好的策略以及提升策略的多样性。
姚蒙
中国科学院自动化研究所,智能系统与工程研究中心
我看了代码,输入state似乎没有做归一化,有些类别特征也没有做one-hot编码,请问有没有必要做呢?坦克射击似乎是自动的?战车的ai好像没有看到。
请教一下,战车的引导射击,改变状态等动作该怎么设计呢?
输入state的归一化有必要做一下,这个版本比较简单暂时还没加,one-hot编码也可以尝试一下,具体效果可能还要看网络设计,个人认为对特征多做一些丰富也是比较好的;这个基准AI版本坦克、战车、步兵的射击都是自动的,模型专注在学习如何move;minigame2想定中战车没有引导射击,除了pass75是主要为战车设计的动作,其他的和坦克都是一样的,网络是集中式的控制方式,输出的时候会输出这一时刻所有算子决策的动作,您可以再看一下代码,有什么问题欢迎随时联系;
我看了代码,输入state似乎没有做归一化,有些类别特征也没有做one-hot编码,请问有没有必要做呢?坦克射击似乎是自动的?战车的ai好像没有看到。
请教一下,战车的引导射击,改变......



