
社区论坛
Community Forum
基于状态影响力模型的探索方法
Exploration via State Influence Modeling
研究背景
奖励环境下的复杂探索任务是极具挑战性的研究课题。 本文关注稀疏奖励环境中探索问题的第一个阶段——无奖励探索阶段。在传统的方法中,比如基于计数的方法(count-based)、基于好奇心(curiosity)的方法等,在这一阶段的表现并不令人满意,因为这些算法只关注单个状态自身的性质,而忽略了状态之间的影响。
解决方案
本文指出,只用状态自身的属性来设计内部奖励,不足以指导智能体完成无奖励阶段的探索任务。状态之间的关系应该作为内部奖励的一个新的部分 被引入。根据社会影响力中对个体的影响力的定义和判断方法,我们为强化学习中的智能体设计了相似的度量方法,该方法同时考虑了对状态自身的评价和状态之间关联关系的评价。
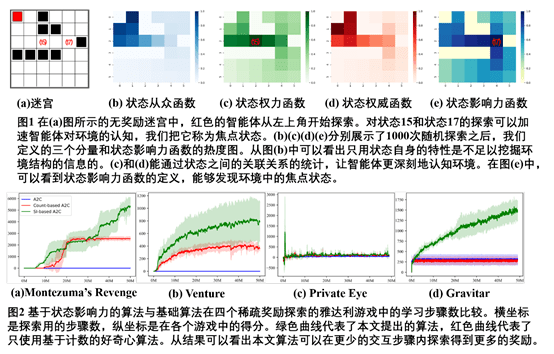
在强化学习的探索任务中,我们把遇到的每一个状态看作一个个体,把它的访问特征看作意见。通过对状态影响力(state influence)的度量(包括三个部分,从众性(conformity), 权力(power),和权威(authority)),智能体能够在没有奖励的情况下,尽快找到已经见过的状态中哪些是焦点状态,通过对焦点状态的进一步探索来提升对当前局部环境的认知能力。其中,从众性函数度量一个状态被访问的频率;状态权力函数定义为多少个状态必须通过与当前状态的信息交换来达到最终目标,它度量了状态之间的关系,可以看作是一个局部探索环境的结构;状态权威函数定义为一个状态的缺席对其他状态的影响,它衡量的是状态之间的另一种关系,表明一个特定状态可以达到多少个未来状态。
基于对状态影响力的定义,我们设计了应用Q-Learning和A2C的通用强化学习框架。并应用到迷宫格与雅达利游戏等带有稀疏奖励信号的复杂探索任务中,得到了比只用状态自身信息设计内部奖励的相关方法更好的效果。
Yongxin Kang, Enmin Zhao, Kai Li, Junliang Xing :Exploration via State Influence Modeling. The Thirty-Fifth AAAI Conference on Artificial Intelligence (AAAI) 2021
康永欣,赵恩民,李凯,兴军亮
中国科学院自动化研究所,智能系统与工程研究中心


